Google ranks pages on a query. AI engines select sources for an answer. The two systems use different signals, so a site can sit in the Google top ten and still be missed by ChatGPT, Perplexity, and Google AI Overviews. Ahrefs research found only 12% of URLs cited by AI tools also rank in the Google top ten for the same prompt. The gap usually sits in five places: weak structured data, no original statistics, thin knowledge graph presence, low brand co-occurrence on trusted sites, and a format that does not fit how an AI engine reads the question.
Your site ranks. You can pull up Google on your phone, type the question your buyers ask, and watch your page sit at the top of the screen. Then a customer messages you and says "ChatGPT recommended someone else." That stings.
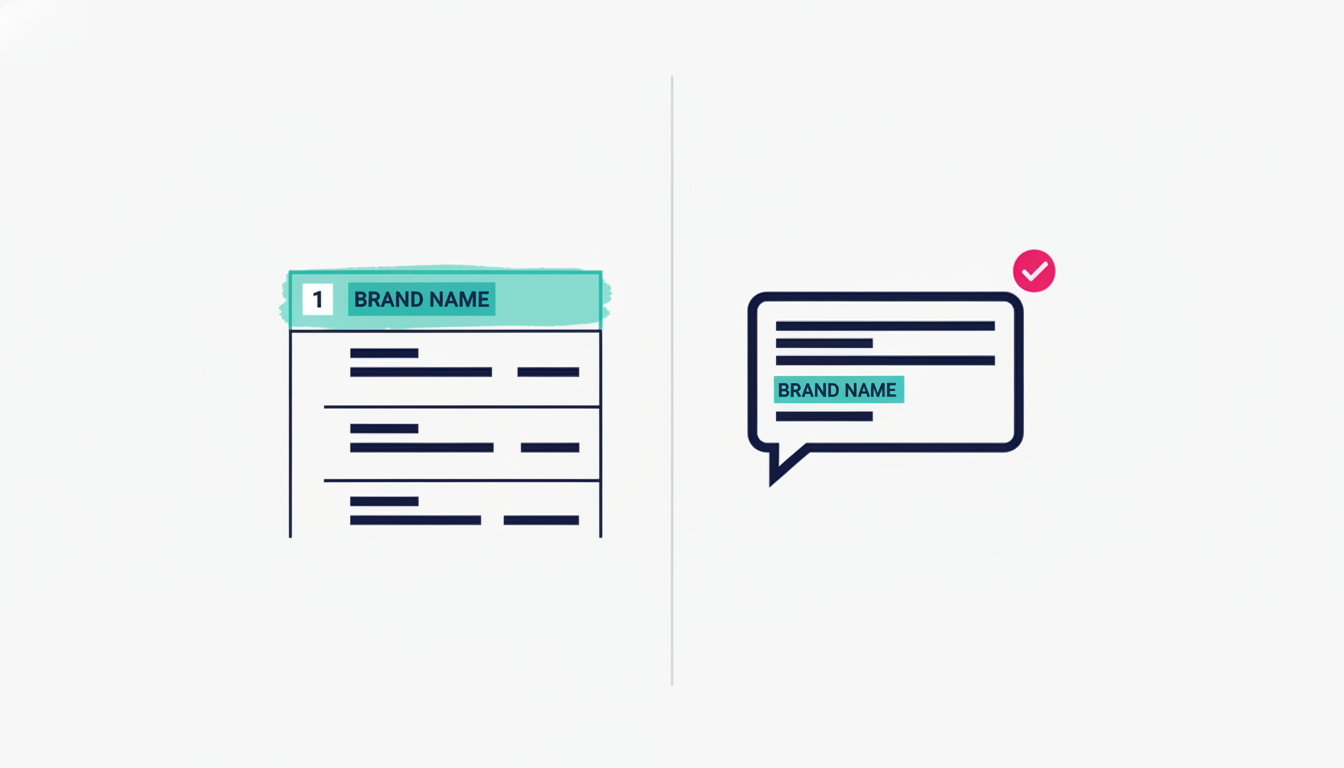
Here is the short answer. Google ranks pages on a query. AI engines select sources for an answer. The two use different signals. A site can win the first system and still be missed by the second. This piece walks the five gaps that most often explain it, with what the research says and what you can check this week.
TL;DR
Google rewards rank. AI engines reward fitness as a citation. The gap usually sits in five places. Weak structured data. No original statistics. Low entity strength in a knowledge graph. Few brand mentions on trusted third-party sites. A content format that does not match how an AI engine reads the question. Ahrefs research found that only 12% of AI-cited URLs rank in Google's top ten for the same prompt. Ranking is not enough on its own.
The two systems are different
Most owners assume Google rank is the goal. For ten years it was. The mental model needs an update.
Google ranks pages. It looks at one query, scores pages on relevance, links, and user signals, and serves a list. The page at the top wins clicks. That model is twenty years old. It works.
AI engines, by contrast, do not serve a list. They write an answer. To do that, they run a process called Retrieval Augmented Generation, or RAG for short. Most AI answer engines use a four-step process: read the user intent, retrieve a set of candidate sources, synthesise an answer, and cite the sources that proved the claim. That is the loop ChatGPT, Perplexity, Gemini, and Google AI Overviews share at a high level.
The candidate set is bigger than the Google top ten. It is also chosen on different signals. The retrieval step uses vector embeddings, which match meaning, not keywords. The citation step picks sources that gave the strongest backing to the claim, not the best-ranked page on the original query.
This is why your site can rank and still be invisible. The new system is not a continuation of the old one. It is a different scorecard.
The hard data on the gap
The gap is not small.
Ahrefs analysed 1.9 million citations from AI engines and found only 12% of URLs cited by AI tools rank in Google's top ten for the original prompt. The other 88% sit elsewhere. Some sit on page two of Google. Many do not rank for that query at all.
A follow-up study from Ahrefs looked specifically at Google AI Overviews. In an earlier sample, 76% of AI Overview citations came from the top ten. In a later, larger sample of 863,000 keyword SERPs and roughly 4 million AI Overview URLs, that figure fell to 38%. About 31% of all AI Overview citations came from pages that do not rank in the top 100 for the same keyword.
What this means for you. The thing that earned your Google rank may not be the thing that earns an AI citation. Think of them as two scoreboards on the same wall.
The five gaps that most often explain it
Most small businesses with this problem have one or more of the following gaps. Run through them in order.
Gap 1. Weak or missing structured data
AI engines parse content faster when it is marked up. Google Search Central recommends JSON-LD as the format. Schema.org is the shared vocabulary.
Pages with structured data make it easier for an AI engine to know what your content is about, who said it, and what category it belongs to. Without schema, the engine has to guess. Guessing costs the engine compute, and other content with cleaner signals beats yours to the citation.
The simple test is to copy a URL into Google's Rich Results Test. If the tool shows nothing, you have no schema. Common gaps are missing Organization schema, missing Article schema on blog pages, and missing FAQ schema on Q-and-A pages.
This is the easiest gap to close. Most CMS platforms add schema with a plugin. The lift is technical, not strategic.
Gap 2. No original statistics or quotable data
The Princeton GEO study, published at the KDD 2024 academic conference, tested six content moves on AI visibility across 10,000 queries on ten engines. Three moves stood out. Adding statistics lifted visibility by 41%. Adding direct quotations lifted it by 28%. Citing external sources lifted visibility by 115% for content that did not already rank in the top three.
Read that last number again. Citing sources more than doubled visibility for lower-ranked pages.
If your top pages are general overviews with no numbers, no quoted experts, no citations, and no original data, the AI engine has nothing to anchor a citation to. It picks a different page that gave it the proof it needed.
The check is fast. Open your top-three pages. Count the statistics with named sources. Count the quotations. Count the external links to credible studies. If the totals are zero or near it, you have found a gap.
Gap 3. Low entity strength in a knowledge graph
AI engines hold a knowledge graph of entities. People. Places. Brands. Categories. The strength of your brand inside that graph affects how confidently the engine recommends you.
Strong entity presence usually shows three signs. A Wikipedia or Wikidata page exists for the brand. The Organization schema on the site uses sameAs to link to the brand's own social and directory profiles. Trusted industry directories list the brand with consistent name, address, and phone data.
If none of those signals exist, the engine has to infer your brand from scratch on every prompt. Other brands with stronger graph presence get cited first. Wikipedia is a primary training data source for many large language models, which is why brands with Wikipedia presence often see a citation lift on prompts about their category.
You will not earn a Wikipedia article overnight. The faster wins are Wikidata, Crunchbase, the right industry directories, and consistent NAP data across them.
Gap 4. Brand co-occurrence is too thin
Models do not build brand recommendations from your site alone. They build them from patterns of co-occurrence across many contexts. The same brand appearing in documentation, peer discussions, analyst reports, and customer forums forms a stronger association than a brand that only appears on its own pages.
This is the gap that ranks-but-not-cited brands hit hardest. Their site is excellent. Nobody else mentions them. The AI engine reads "best dentist in Brisbane" or "best CRM for trades", scans its training data, and finds five brands talked about by other people. Your brand is talked about only by your own site.
The fix is mentions, not links. Be quoted in industry articles. Get listed in the directories your category trusts. Run case studies that other people will reference. Comment on Reddit threads in your niche, since Reddit content is heavily cited by ChatGPT in particular.
This is the slowest gap to close. It is also the highest leverage.
Gap 5. The content format does not match the question
AI engines fan out a single user query into multiple sub-queries before answering. Google calls this query fan-out. Each sub-query pulls its own retrieval set. The pages cited at the end are the pages that appeared most often across the sub-queries.
A page written as a long sales-led overview rarely matches the sub-queries. A page written as a clear answer to a specific question often does.
If your top pages are 4,000-word service pages designed to convince a buyer, they are written for the wrong reader. The engine wants short, direct, structured passages it can pull as a citation. A buyer wants persuasion. You can serve both, but the structured layer needs to exist.
Common format wins are simple. Add an early TL;DR. Answer the primary question in the first 150 words. Write sub-headings as the questions a customer would type. Add an FAQ block at the end of the page.
How to tell which gap you have
You do not need to fix all five at once. Find the one that is biggest in your case.
Start by running a free AI visibility check across ChatGPT, Perplexity, and Gemini for the prompts your buyers ask. Note where you appear and where you are missing.
Then run the three quick audits below.
- Schema audit. Paste your top-three URLs into Google's Rich Results Test. Note what is there and what is missing.
- Data audit. Open the same three URLs. Count statistics with named sources, direct quotations, and external citations. If your totals are low, gap two is real.
- Entity audit. Search your brand on Wikipedia, Wikidata, Crunchbase, and the two largest directories in your industry. If the count of strong listings is below five, gap three is real.
The audit takes an hour. It saves you weeks of guessing.
The order I would fix the gaps
If I were sitting next to you, I would pick this order. It moves from cheapest to slowest.
- Add or repair structured data on your top-three pages.
- Insert one statistic with a named source and one direct quotation into each of those pages.
- Add an early TL;DR and turn the H2 headings into the actual questions a buyer would type.
- Claim or update your Wikidata, Crunchbase, and the two best directories in your category.
- Plan one earned mention this quarter, a quote in an industry piece, a comment on a respected Reddit thread, or a guest article on a recognised site.
Steps one to three are content work that you control. Steps four and five depend on other people. Start with one to three this week. Steps four and five run in the background.
Two short scenarios
A wellness clinic with strong Google rank. The owner's site sits at position two for "naturopath in Newcastle". A buyer asks ChatGPT the same thing. Two other clinics are recommended. The clinic's pages have no Organization schema, no statistics on the service pages, and no Wikipedia or Wikidata presence. Three gaps. The fastest fix is schema and statistics inside two weeks. Wikidata and directory work follows over the quarter.
A trades business that wins on Google for "best plumber Sydney". The site ranks. ChatGPT ignores it. The site has Organization schema and a steady directory presence. The gap is co-occurrence. No reviews quoted in trade press. No mentions on home renovation forums. The fix is digital PR, not on-page SEO. Three guest pieces and one strong forum presence over the quarter close most of the gap.
The point is not that Google rank is wasted. It is the floor. AI citation is the next layer of work, on a different scorecard.
Sources
- Aggarwal, P. et al. GEO: Generative Engine Optimization. Princeton University, Georgia Tech, Allen Institute for AI, IIT Delhi. KDD 2024 peer-reviewed.
- Ahrefs. Only 12% of AI cited URLs rank in Google's top 10 for the original prompt. Original data study.
- Ahrefs. Update: 38% of AI Overview citations pull from the top 10. Follow-up data study.
- Pew Research Center. 34% of US adults have used ChatGPT, about double the share in 2023. June 2025.
- Google Search Central. Intro to how structured data markup works. Official documentation.
- Search Engine Land. How different AI engines generate and cite answers. Industry trade press.